

Data Mesh Architecture With dbt-core and Teradata
Learn to implement a data mesh architecture with dbt-core and free and open-source plug-ins.
The why and what of the data mesh architecture
Typical dbt implementations involve single-project setups comprising a collection of models. The data in such projects is modeled to represent entities and events of interest across all organizational domains.
As the needs of data consumers expand, more models are incorporated into the dbt project to cover a wider array of entities and events. However, as the project scales, the task of tracking data and its lineage can become overwhelming, leading to greater complexity in debugging and maintenance efforts.
Data mesh is an architectural approach that entails decomposing intricate data architectures into interconnected smaller, more manageable elements tailored to specialized business domains.
These elements expose specific datasets, adhering to designated data contracts, to data consumers. The data mesh architecture simplifies maintainability, data governance, and data democratization in complex dbt implementations.
Data mesh in dbt
Cross-project dependencies were not easy to implement in dbt. It’s always been possible to import external packages as dependencies. However, this strategy didn’t quite support data mesh scenarios. Cross-database/schema references weren’t possible. Moreover, there was no mechanism in place for implementing both public and private visibility settings on referenced models, deviating from best practices in data governance.
Since 2023, dbt started providing native support for data mesh architectures through dbt-cloud. There are scenarios, however, where organizations may not have access to dbt-cloud. Fortunately, free and open-source dbt plug-ins like dbt-loom make it feasible to implement a data mesh architecture using dbt-core. This empowers all dbt users to incorporate a data mesh architecture into their dbt implementations.
In this article, we delve into the process of implementing a data mesh architecture utilizing dbt-core alongside free and open-source plug-ins.
Business background
An organization, Teddy Retailers, is architecting a dbt implementation to serve data related to the following organizational domains:
- Inventory
- Product catalog
- Incoming stock and purchase prices
- Sales
- Customer directory
- Orders
- Finance
- Monthly profit and loss statement
Regarding this implementation, the operational sources are as follows:
- Inventory
- Product catalog: product id, product name, product category, current market price
- Stock entries: entry id, product id, product quantity, purchase price
- Sales
- Orders: order id, customer id, order status, order date
- Order products: transaction id, order id, product id, product quantity
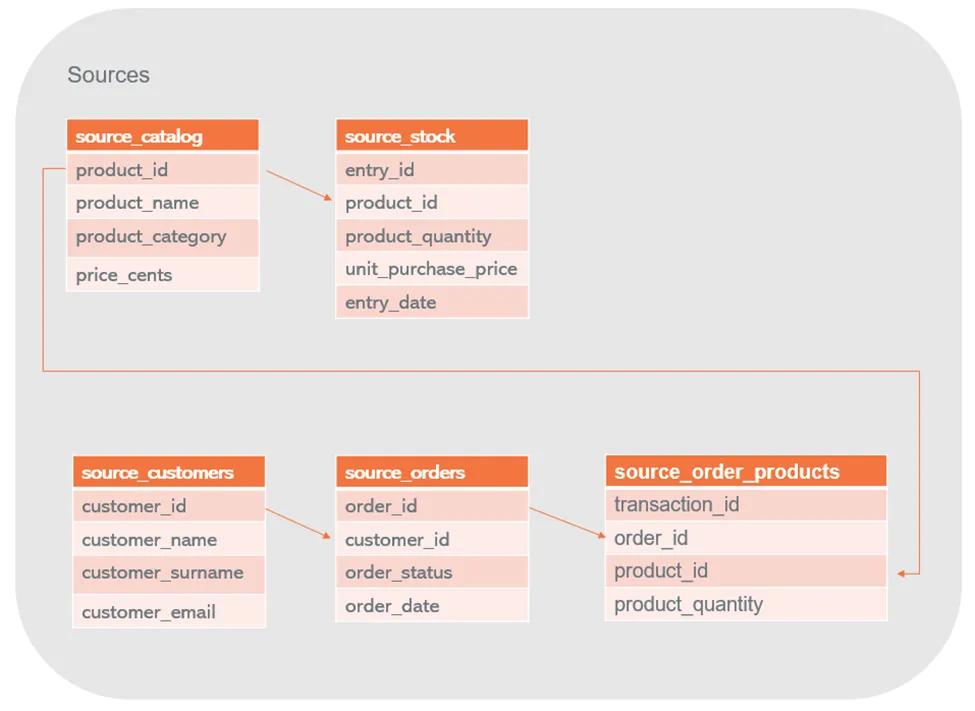
Diagram of sources mentioned in the previous paragraphs.
From these sources, we’re going to build a multi-project dbt data mesh with the following projects:
- Inventory:
- Will expose models for a product catalog and state of product stock per calendar month. The latter model will involve calculating the quantity of each product acquired each month and the average price of acquisition of each product in that period.
- Sales:
- Will expose models for a customer directory, including a calculation of each customer total lifetime value (TLV). The TLV calculation requires price data from the product catalog in the inventory domain. Also, this project will expose an order summary, which includes a calculation of the total value of each order. This public model also requires access to price data from the product catalog.
- Finance:
- Will expose an order profit-and-loss model. This model involves calculating the total cost and total value of orders. To perform these calculations, pricing and cost data from the sales and inventory domains, respectively, are necessary.
The final diagram of the data mesh project is as follows:
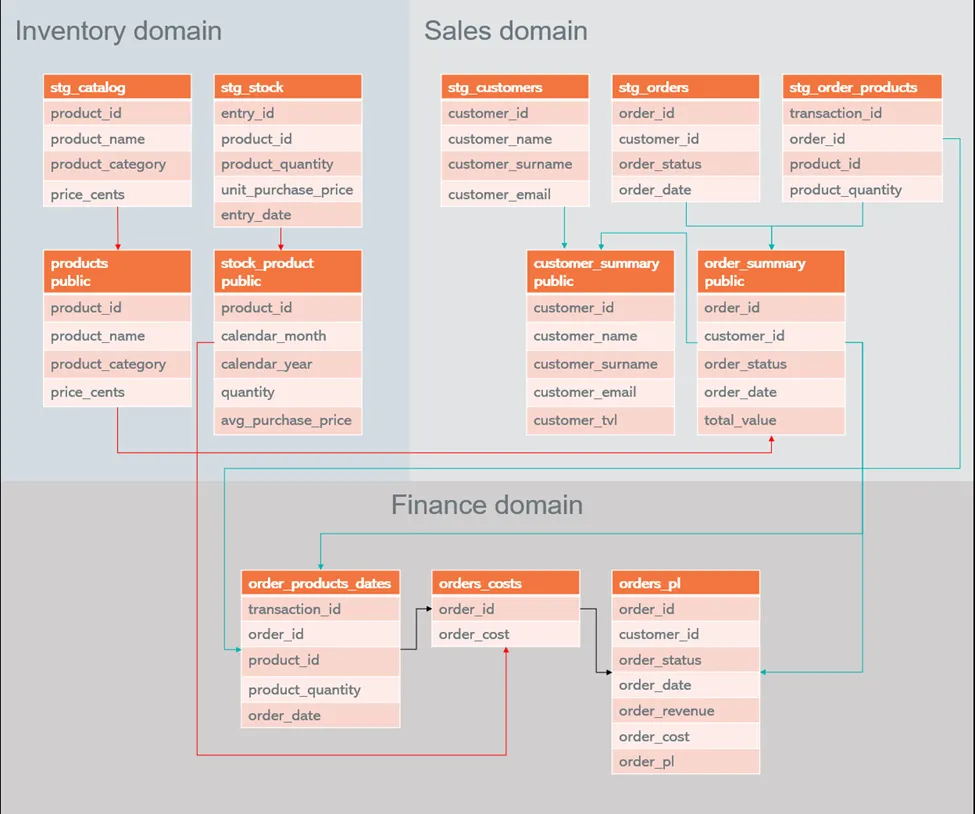
Diagram of interdependent projects in the data mesh
In this article, we’re focusing on the data mesh as a data architecture and how to implement it in dbt-core with open-source plug-ins. Covering the queries that materialize each of the models in the project is not the focus. The logic followed can be referenced from the accompanying GitHub repository.
Sample data mesh with dbt-teradata, dbt-loom, and Teradata VantageCloud
Requirements
- An instance of Teradata VantageCloud, which you can provision for free at ClearScape Analytics™ Experience.
- A database client to connect to your Teradata VantageCloud instance.
- Cloning of the data mesh repository to a local directory.
- The repository contains two directories. The `references` directory contains standalone SQL scripts to run in your database client, as described below. The `projects` directory contains the dbt projects.
Loading sample data
To load sample data for each project in the data mesh, a dedicated database must be created and populated with specific source data. This process involves executing SQL commands in your chosen database client.
- Begin by executing the command to create the databases, which can be found in the `references/inserts/create_db.sql` file within the data mesh repository.
- Once the databases are created, proceed to execute the command for loading the data sources, located in `references/inserts/create_data.sql` within the data mesh repository.
Running command for database creation with dbeaver as a client
Setting up development environment
For convenience, we recommend keeping a single Python virtual environment for installing the dependencies of the three data mesh projects.
- Navigate to the `projects` directory in your local data mesh repository and create and activate a Python virtual environment (at the time of writing, the latest Python version supported is 3.11).
- Install dbt-teradata: `pip install dbt-teradata`
- Install the dbt-loom plugin: `pip install dbt-loom`
Copy the contents of `projects/profiles-sample.yml` to your home’s directory `.dbt/profiles.yml` file. If this file doesn’t exist in your system, you’ll need to create it.
In your edited `.dbt/profiles.yml`, change the values of host, username, and password according to your Teradata VantageCloud configuration for the three projects.
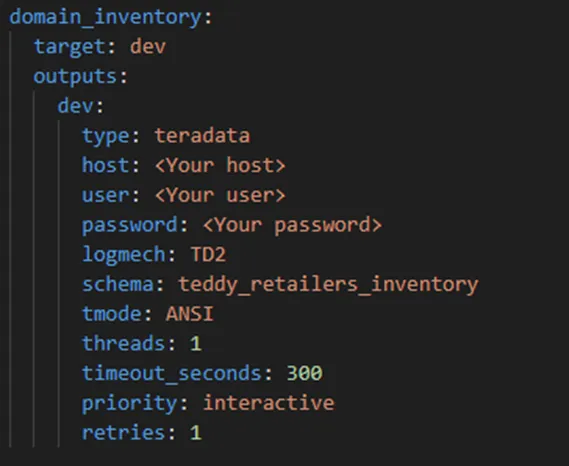
Illustration of project configuration in .dbt/profiles.yml
What is different in a dbt data mesh project?
The main characteristic of a data mesh implementation is that the projects involved can reference models from other projects, which are frequently materialized in distinct schemas or databases. Referencing projects requires clear references to access the necessary materializations. Conversely, referenced projects require a mechanism to designate specific models as shareable across domain boundaries and to delineate constraints, ensuring that referencing models understand what data to expect and adapt gracefully to any changes.
In our sample data mesh, we utilize dbt-loom, a free and open-source plug-in, to facilitate this cross-model referencing. Setting up a data mesh enabled by dbt-loom is quite straightforward.
- For referenced projects:
- Public models should be defined as `public` explicitly in their corresponding `schema.yml` file
- A data contract should be defined for each public model
In our data mesh, the `domain_inventory` project illustrates how a referenced project that doesn’t reference any other project is configured.
As seen in the following model, the model definition is the same as in a regular dbt project.
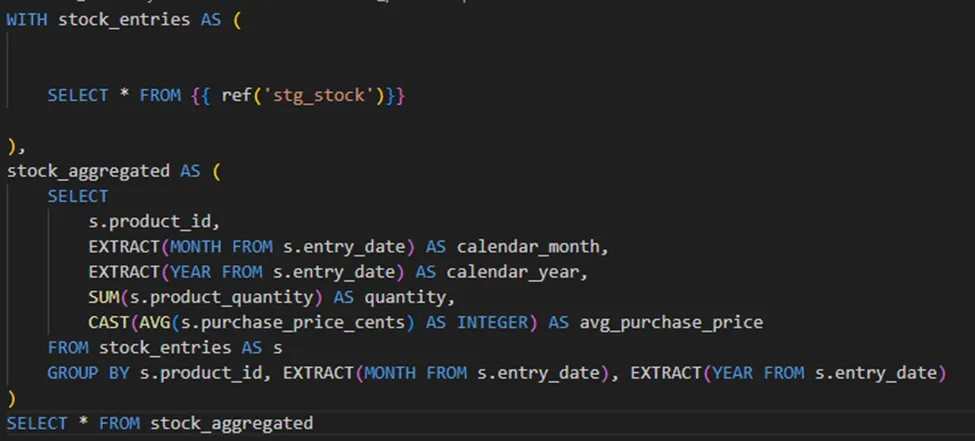
Definition of the `stock_products` model in the inventory domain
The configuration of the model, as articulated in the schema.yml of the corresponding model, encapsulates the requirements mentioned above.
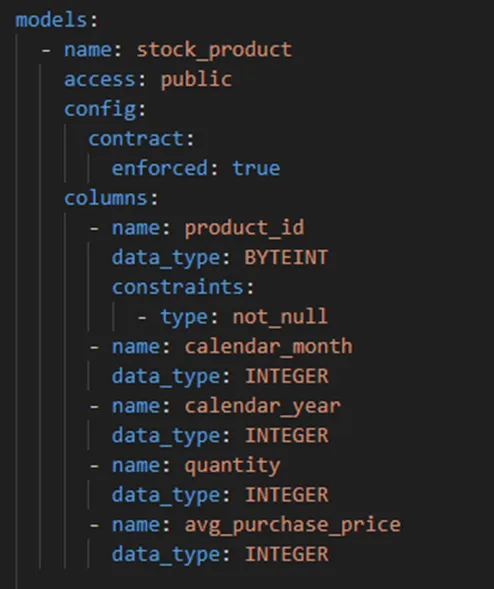
Configuration of the `stock_products` model in the inventory domain
- For referencing projects:
- dbt-loom works by integrating the referenced models into the Directed Acyclic Graph (DAG) of the referencing project. This process relies on the information provided in the `manifest.json` file of the referenced project.
- For the reason above, a referencing project must include a `dbt-loom.config.yml` file. This file points to the location of the `manifest.json` of each of the external projects referenced.
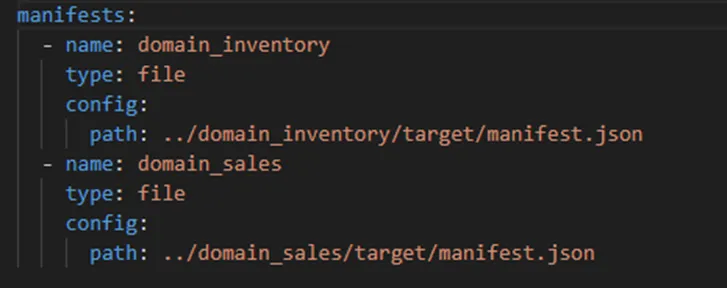
`dbt-loom.config.yml` of the finance domain project in our data mesh sample
In this specific example, the `manifest.json` is retrieved from a local file. In a production environment, the servers running each project might be different and might not have access to each other. For these cases, dbt-loom also supports fetching the `manifest.json` from cloud providers. Of course, in these scenarios a strategy is needed to export the `manifest.json` to the cloud location after each compilation.
- With this configuration file defined, models in the referencing project can reference public models in the referenced projects. As shown in the image below, the reference takes the form of `ref(“referenced-project”,”referenced-model”)`
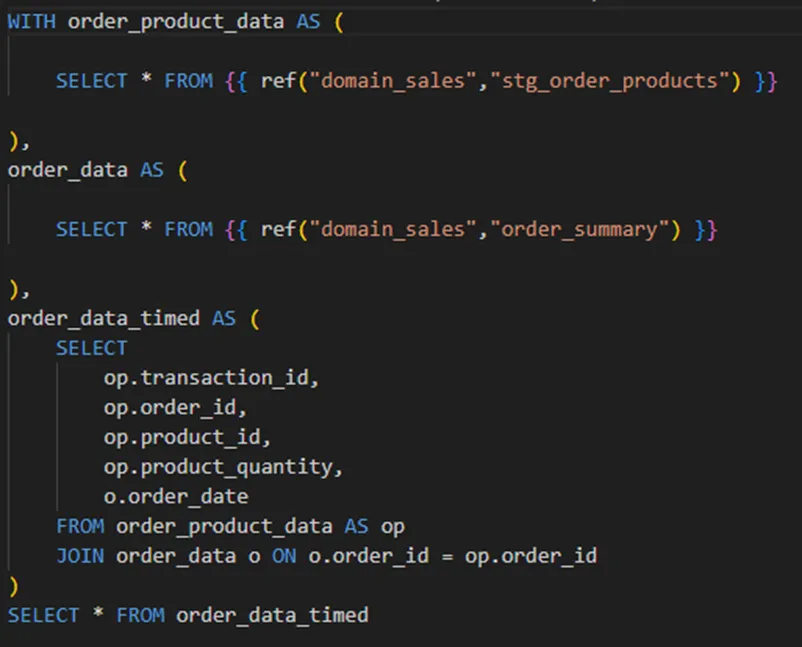
Definition of the `order_products_dates` model in the finance domain
Projects that are both referencing and referenced should comply with both categories' requirements. Define public models and their respective contracts, and include a `dbt-loom.config.yml` file as described above. The project `domain_sales` in our data mesh sample is an illustration of such a project.
Running the sample data mesh
Navigate to the directory of each data mesh project and, with your virtual environment activated, execute the following commands:
- `dbt debug` to make sure the projects are properly connecting to your Teradata VantageCloud instance
- `dbt run` for running the project
The first time you replicate the data mesh, make sure to start from the inventory domain, followed by the sales domain, followed by the finance domain. Referenced project materializations and manifests should be generated before other projects can reference them.
When executing a referencing project, we can observe dbt-loom injecting the referenced models as part of the execution of the DAG of the referencing project.
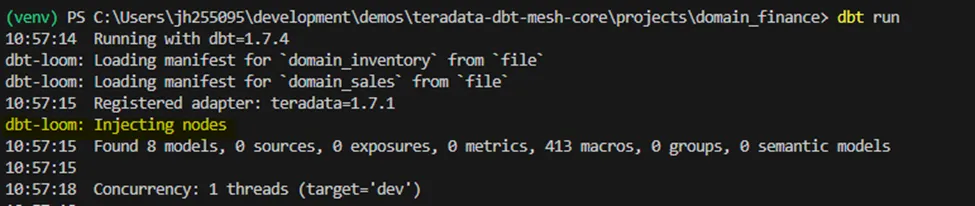
dbt-loom injecting referenced models as part of the DAG execution of the referencing project
Final considerations
dbt-loom, as a free and open-source project, does specify certain caveats related to the use of dbt-plugins. It’s worth mentioning that documentation and lineage generated by `dbt docs generate` don’t reflect the provenance of referenced models in detail, as related to their home project.
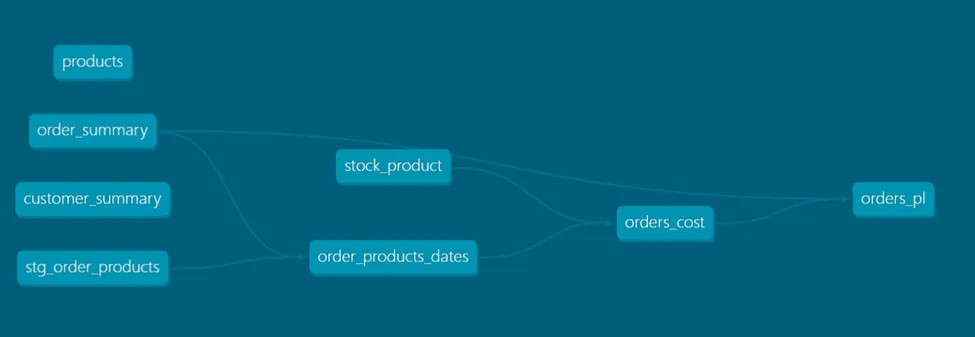
Lineage graph of the domain_finance project in our data mesh sample
Having said that, the data mesh represents a data architecture concept that can significantly enhance maintainability, data governance, and data democratization within intricate dbt implementations. dbt-loom serves as a gateway to implementing this architecture in scenarios where access to dbt-cloud is not feasible.
Restez au courant
Abonnez-vous au blog de Teradata pour recevoir des informations hebdomadaires